Using AI to refine structured descriptions of products in Shopify to maximize the customer experience.




Building on our previous post’s conceptual framework, this article examines the real-world implementation of a two-stage AI content processing workflow that reduced content processing costs by over 90%.
How I saved an e-commerce business $20,000+ in labor costs with $33 in API calls and a couple Python scripts
A client had over 2,000 products on Shopify, with 1,172 “Active” products needing HTML code restructuring and content updating. After acquiring a 30-year-old business and migrating from Magento to Shopify, they lacked the time and capacity to review and restructure product HTML without investing hundreds of hours. Most pages had sufficient content but needed reformatting and cleanup, while others required additional information and a full revamp that was compatible with their custom CSS code.
For this problem, I used the product title, body HTML code, short description meta-data and, if available, product manuals to prompt the genAI models to generate the target content. The goal was to implement a solution that enhances quality and information (useful to the customer) that, hopefully, enhances ranking. Search engines such as google have made updates to stay ahead of the AI spam, so quality over quantity remains essential.

To simplify future edits and empower the client, I used the Matrixify app instead of Shopify’s developer API. The client is already familiar with Matrixify, and it allowed me to deliver results in under 30 days for just one month’s usage ($50). This approach provides structured, reusable data the client can retain or revert to later. Hence, it offered both flexibility and cost savings in the long term.
The content generation focus was aligned with the clients’ goals:
Standardize Header Structure for Efficient Crawling:
Normalize use of headers (H3 for main, H4 for sections, H5 for subsections)
Eliminate inconsistent use of H1/H2 which harmed SEO
Ensure header structure integrates with custom CSS for styling consistency
Responsive, Clean HTML Formatting:
Reformat HTML to be compatible with their custom CSS, particularly:
Bullet lists
Image/video/link containers
H3–H5 headers
Avoid inline styles and unnecessary formatting
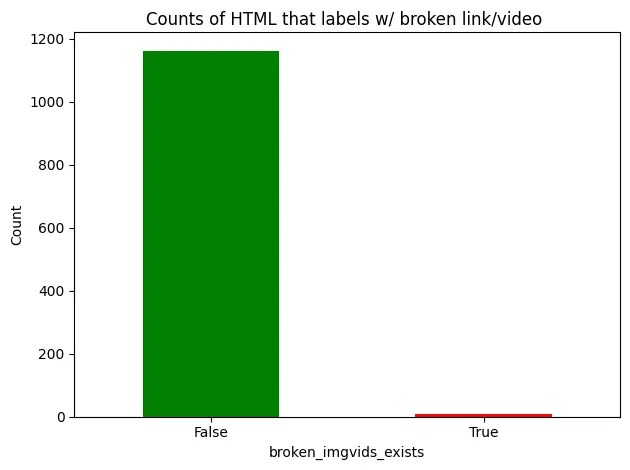
Fix or Flag Broken Media/Links:
Automatically identify and report any broken images, videos or links
Short Description Integration:
Merge “short description” meta-data more fluidly into the full product description, especially when it appears before a proper header
Model Choice: GPT-4o (initially tested GPT-4o-mini, but 4o followed instructions better on long HTML pages). I used a lower temperature to reduce “creativity” and make the output more focused, predictable and repeatable (see discussion of temperature in LLMs here)
modify_html_with_gpt(prompt=prompt_user, sys_prompt=prompt_system, model="gpt-4o", max_tokens=8000, temp=.3)I used data-driven cutoffs based on the word count distribution (first quartile at 27 words) across products, with randomized target lengths between first (27) and second (84) quartiles.

While LLMs are bad at counting, my hope was that it would perform decently enough to use the randomization in some way downstream. As expected, the genAI agent often overshot the target word count. This limits my ability to evaluate whether randomly assigning word counts alters key KPIs for the client.

The goals for the validation were:
Model Choice: Claude-3.7-Sonnet for validation
modify_html_with_anthropic(prompt=prompt_user, sys_prompt=prompt_system, model="claude-3-7-sonnet-latest", max_tokens=8000, temp=.3)Different model families reduce systematic bias and provide strong analytical capabilities for content evaluation. As some have discussed different strengths of OpenAI versus Anthropic models, I, too, find that sonnet genAI performs relatively well at identifying factual errors, coding bugs and, in some ways, not being as verbose.
I evaluated several metrics for Stage 1 and Stage 2, specifically:
Semantic Similarity: Using sentence-transformers/all-MiniLM-L6-v2 model to measure content meaning preservation through cosine similarity in 384-dimensional space (1 = perfect preservation; 0 = no preservation).
Edit Similarity: Compares word arrays to identify unnecessary changes in already adequate content. For example, “I love pizza” vs “Pizza is great” = 0.33 (1 = perfect similarity, 0 = no similarity).
Content Preservation: This evaluate how much of the unique content is preserved in each description. For example, if the original body contains “the red car is fast” and the new body contained “the blue car is slow” there are 3 shared words (the car is) / 7 total unique words (the red blue car is fast slow), so the preservation (or Dice coefficient) = 0.43 (1 = perfect preservation, 0 = no preservation).
As expected, the variability was greatest in these metrics during stage 1. Specifically, the semantic similarly was high between the original and GPT-produced text. Given that we were wanting to restructure more text and, in some cases, gave the model the product manual, it is not surprising that some words changed.

In stage 2, I was focused on “cleaning up”. So my expectation for broad changes across each of the three metrics was low. This was affirmed by the calculated metrics. While some things did get corrected and reorganized, it was to a minimal extent.

The added value was that both stage 1 and stage 2 flagged products with dead links (404) and broken images/videos. Specifically, stage 1 caught errors and stage 2 found additional errors, demonstrating the value of a second pass.
>> “It’s the best use of AI that I’ve seen so far”
Based on client’s rolling 365-day data:
* Conservative estimates: 3% visitor increase + 0.05% conversion improvement = $11,585 additional monthly revenue, easily justifying the investment.
* hypothetical projection.
This was a first pass by the client to take care of the “low hanging fruit”. After my report highlighting:
They intend to revisit and make additional updates using this framework. Given that the code is written, it can be easily reapplied on the descriptions.
This two-stage AI workflow delivered a 95% reduction in processing time while significantly improving content quality. The key to success lies in treating AI as a collaborative tool, using quality metrics for continuous improvement, and designing scalable systems that maintain quality standards.
As a bonus, I provided SEO title and meta description updates for content pages for ~$0.50 in API costs (see genAI for SEO metadata). Demonstrating the multi-faceted utility of these tools.
Want to see how this approach can work for your business and/or products?
Contact us to discuss your specific needs and explore implementation options tailored to your business.




